AI-Aided
Author Info
Background
The paper identifies a critical bottleneck in deploying Large Language Models (LLMs):
- The Optimization Challenge: Efficient deployment requires tuning a vast configuration space (e.g., parallelism strategies, batch sizes, caching policies).
- Cost vs. Fidelity Trade-off:
- Real GPU Execution: Testing on physical hardware is prohibitively expensive and slow.
- Discrete-Event Simulators (DES): While fast and cheap, traditional simulators require manually re-implementing the serving system’s complex control logic. Because frameworks (like vLLM and SGLang) evolve rapidly, simulators suffer from a perpetual “semantic gap” and high maintenance burden.
Insights
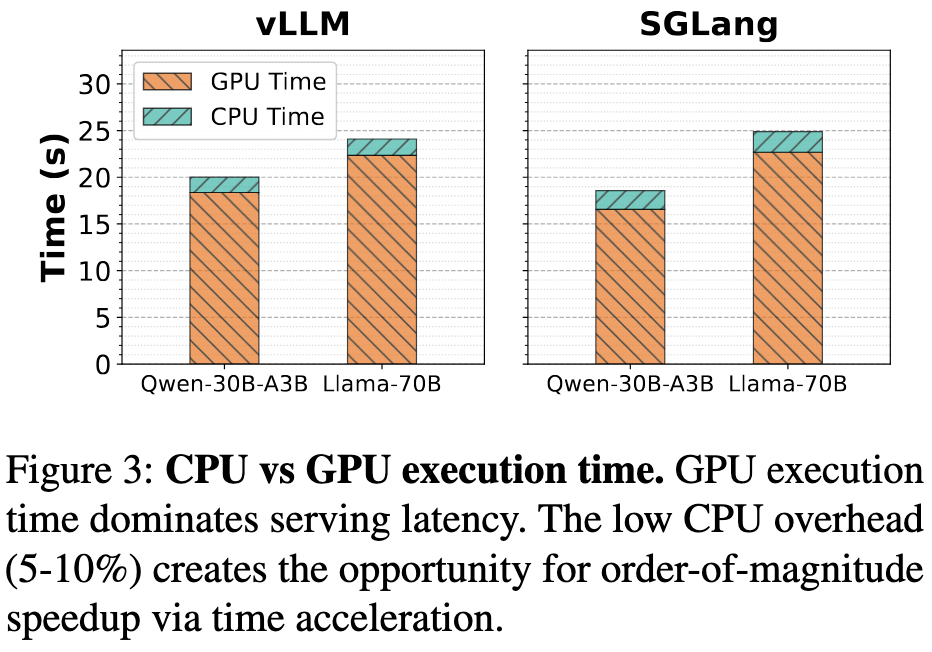
LLM serving systems spend 90-95% of their wall-clock time waiting for GPU operations to complete. The CPU control plane (scheduling, memory management) is fast and largely decoupled from the actual values computed by the GPU.

Revati replaces physical GPU execution with “virtual time jumps.” Instead of waiting for a GPU kernel to finish, the system fast-forwards the virtual clock by the predicted duration of that kernel.
Instead of simulating the logic, Revati executes the actual unmodified source code of the serving system (e.g., vLLM, SGLang).
Approaches
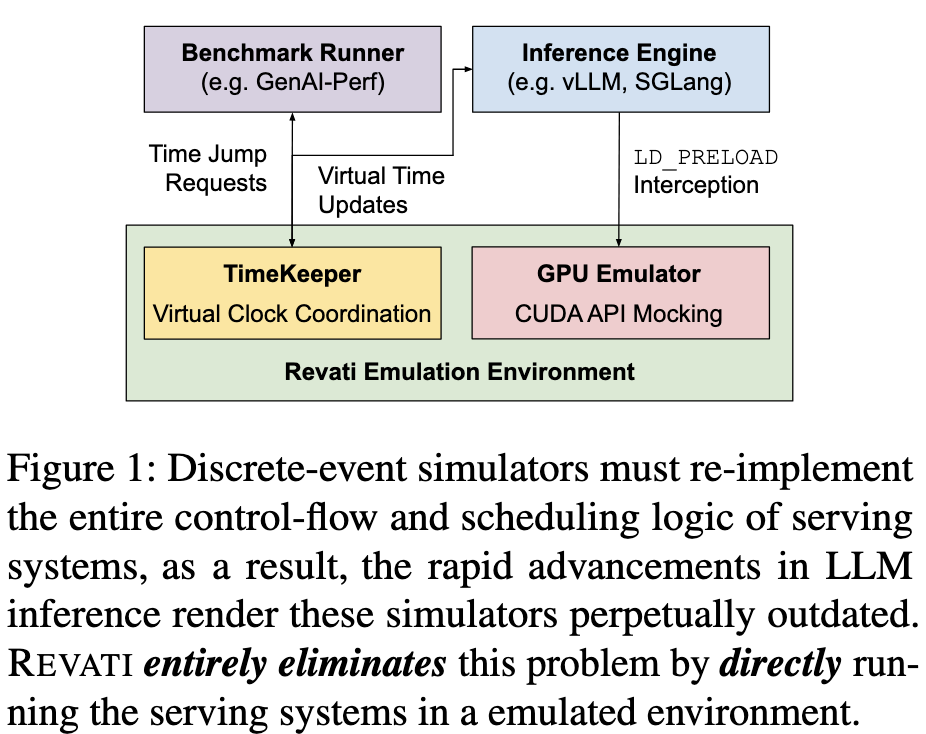
Transparent Device Virtualization
- Interception: The system uses
LD_PRELOADto intercept CUDA API calls. It presents virtual devices to the serving framework, allowing the code to run as if GPUs were present. - Split-State Memory Model: To handle memory without a GPU, Revati bifurcates allocations:
- Metadata Buffers: Small allocations used for control flow are backed by real host memory so the CPU can read them.
- Compute Buffers: Large allocations (like KV caches) are given virtual pointers. Operations on them are treated as no-ops, preventing memory overhead while maintaining logical consistency.
The Timekeeper & Coordination Protocol
Since serving systems are distributed (involving schedulers, workers, and load generators), simply skipping time locally would violate causality (e.g., a request arriving “after” a batch finishes in virtual time, when it should have arrived during execution).
- Centralized Timekeeper: A dedicated service coordinates the virtual clock across all processes.
- Barrier-Based Synchronization:
- Actors (components with predictable durations, like GPU workers) request a time jump based on a performance model.
- The Timekeeper collects requests and advances the global virtual time only to the minimum requested target.
Runtime Prediction
To accurately determine how far to jump the clock, Revati uses a pluggable runtime predictor. By default, it employs analytical models (similar to those used in the Vidur simulator) to estimate how long a specific kernel or operation would take on the target hardware (e.g., an H100 GPU).
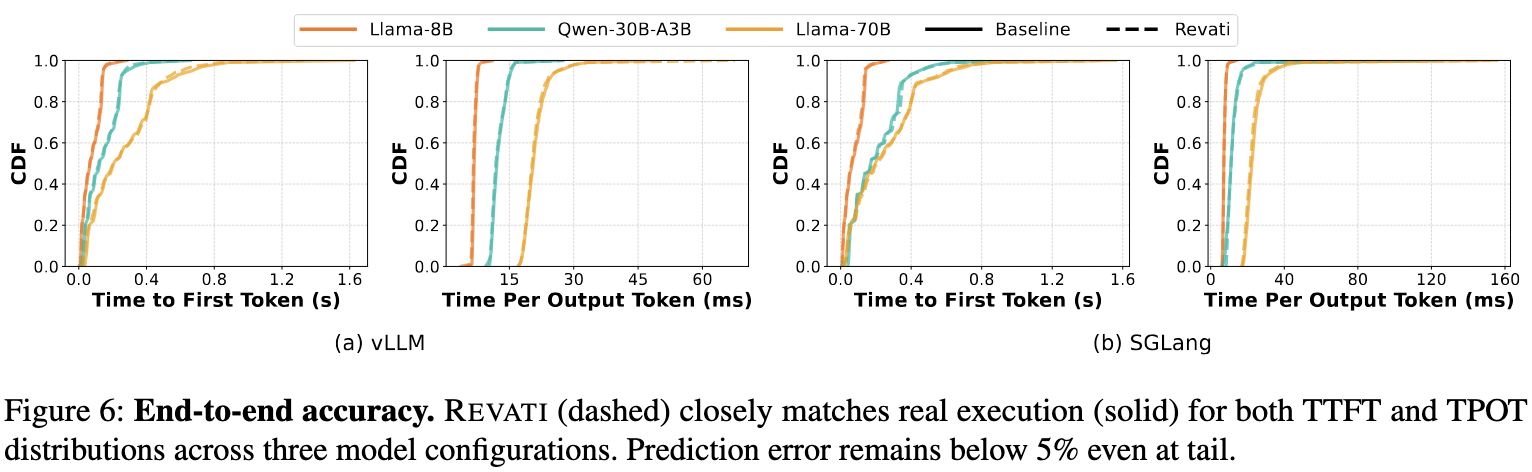
Evaluation