Background
Serverless inference can significantly reduce costs for LLM users by charging only for the duration of inference and the volume of processed data.
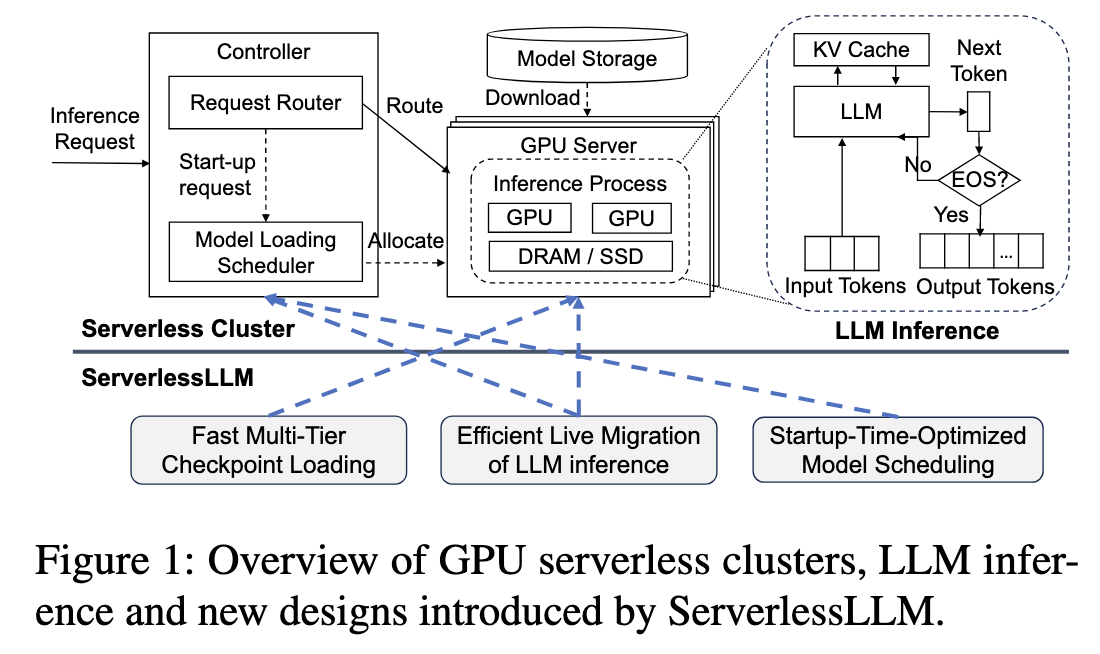
Key components in GPU serverless clusters:
- Controller:
- Request Router: direct incoming requests to nodes already running LLM inference processes, or instructs the model loading scheduler.
- Model Loading Scheduler: activate LLM inference processes on unallocated GPUs.
TODO
The deployment of LLMs on serverless systems, although promising, often incurs significant latency overheads. This is largely due to the substantial proportions of cold-start in serverless clusters.
Two primary reasons for prolonged LLM cold-start latency:
- LLM checkpoints are large, prolonging downloads.
- Loading LLM checkpoints incurs a lengthy process.
Existing solutions:
- Over-subscribing GPUs: maintain a certain number of GPU instances in a warmed state to alleviate the impacts of slow cold starts.
- Costly
- Caching checkpoints in host memory: cache model checkpoints in the host memory of GPU servers to eliminate the need for model downloads.
- Limited size of host memory
- Deploying additional storage servers: additional storage servers within a local cluster to cache model checkpoints
- Costly
Core Insights
充分利用 GPU 推理服务器自身强大但未被充分利用的多层级存储体系
通过利用这些“服务器内”的本地存储资源来缓存模型检查点,并通过优化的加载路径来最大化存储带宽,从而根本性地减少甚至消除从远程下载模型的开销,实现超低延迟的模型加载
ServerlessLLM addresses the challenges highlighted in the previous sections—high model download times and lengthy model loading
通过 In-server multi-tier storage, ServerlessLLM 可以解决下面三个问题:
- Support complex multi-tiered storage hierarchy
- 当前的 Model Check Points 是为训练优化的,而不是为推理优化的
- Strong locality-driven inference
- 尽可能地考虑模型的本地性
- Scheduling models for optimized startup time
- 在调度时,从各方面准确地预估 startup time
Approaches
Fast Multi-Tier Checkpoint Loading
为了最大化利用服务器内部从 SSD 到 DRAM 再到 GPU 的多层级存储带宽,ServerlessLLM 进行了两项创新:
Loading-Optimized Checkpoint
Insight: In serverless inference environments, checkpoints are uploaded once and loaded multiple times.
这种格式将模型的二进制参数数据和元数据分离,并按目标 GPU 对张量进行分区存储,以便进行高效的、大块的顺序读取 。 同时,一个独立的索引文件被创建,用于直接计算每个张量在 GPU 显存中的地址,避免了复杂的解析过程 。
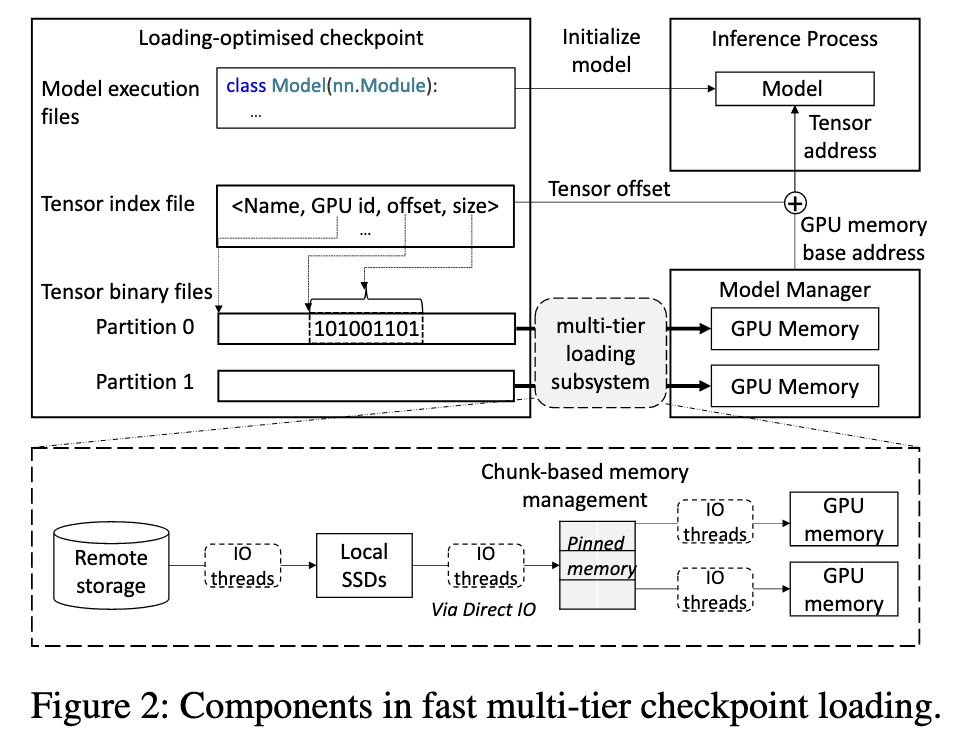
同时,ServerlessLLM 将加载过程解耦:即将「加载模型数据」和「初始化模型推理环境」这两个过程分离开来,并让它们并行执行,以缩短总的启动时间
常规的模型加载是串行的:先初始化模型结构,然后一步步把数据读入并填入结构中。ServerlessLLM 发现,如果将这两个过程分开,就可以让它们重叠进行,从而提升整体加载性能
为了实现解耦,系统引入了两个角色:
- 模型管理器 (Model Manager):负责处理庞大的模型参数数据 。具体来说,它会在 GPU 上预先分配好内存,然后通过一个高效的加载子系统,将检查点中的二进制数据(也就是模型的权重参数)直接载入到这块 GPU 内存中 。
- 推理进程 (Inference Process):负责初始化模型在代码层面的对象(比如 Python 中的模型类),并且为模型中的每一个张量(tensor)设置正确的数据指针,让它们指向模型管理器已经加载好的数据 。
- 指针设置的具体流程 推理进程并不直接接触和搬运数据,它只需要知道数据被放在了哪里。这个“寻址”过程如下:
- 首先,它从模型管理器那里获取每个 GPU 上数据存储区的基地址(base addresses) 。
- 然后,通过读取一个“张量索引文件”,从中查找出每个具体张量相对于基地址的偏移量(offset) 。
- 通过“基地址 + 偏移量”**,推理进程就能计算出每个张量在 GPU 上的确切内存地址 。
在两个过程都完成各自的任务后,为了确保模型在开始真正的推理计算前已经完全准备就绪,模型管理器和推理进程会执行一次同步。
Multi-Tier Loading Subsystem
该子系统的核心目标是实现快速且性能可预测的检查点加载 。它被集成在“模型管理器”中,通过三项关键技术来实现这一目标
- Chunk-based data management
- Utilizing parallel PCIe links
- Supporting application-specific controls
- Mitigating memory fragmentation
- Predictable data path
- Exploiting direct file access
- Exploiting pinned memory
- Multi-tier loading pipeline
- Support for multiple storage interfaces
- Support for intra-tier concurrency
- Employ multiple I/O threads for reading data within each storage tier, improving bandwidth utilization
- Flexible pipeline structure
- A flexible task queue-based pipeline design
- I/O threads read storage chunks and enqueue their indices (offset and size) for the I/O threads in the next tier
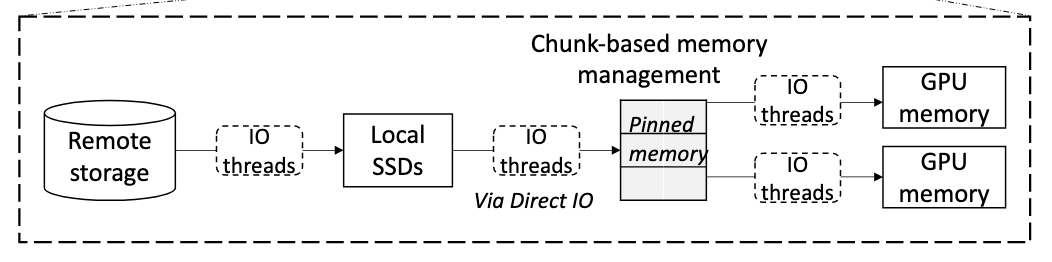
在每一个 Tier 中,每读一个 Chunk 就通知下一个 Tier 的 I/O Thread 进行读取
常规文件读取的问题
- 读请求经过三步:磁盘 → 内核页面缓存 → 用户空间,导致数据被拷贝两次。
- 拷贝消耗 CPU 和内存带宽;首次读取依赖磁盘速度、缓存命中又依赖历史访问,性能波动大。
O_DIRECT(直接文件访问)的优势
- 打开文件时加上 O_DIRECT 标志,可让数据直接从存储设备写入应用程序内存,绕过页面缓存。
- 省去了中间拷贝,降低了 CPU 负载和内存带宽占用。
- 性能可预测,只受存储设备原始读速影响,适合对延迟稳定性要求极高的场景(如 ServerlessLLM)。
常规可分页内存与 GPU 传输的问题
- 大多数主机内存是可分页的,物理地址可能变化,GPU 的 DMA 引擎无法直接可靠地从中读取数据。
- 因此,驱动会先分配一块固定内存(Pinned Memory)作临时缓冲,再由 CPU 将数据从可分页区拷贝到这块固定区,最后 GPU 再通过 DMA 拉取,导致额外的内存拷贝和 CPU 开销。
Pinned Memory 的工作方式
- 通过专门接口(如 cudaMallocHost)申请的一块物理地址恒定的内存,不会被分页或换出。
- 数据可以直接在这块固定内存中读入或存放,无需额外拷贝到临时区。
- GPU 的 DMA 引擎可异步、直接地从固定内存拉取数据到显存,CPU 只需发出传输指令即可继续其他计算。
主要优势
- 消除了主机内存内部的冗余拷贝,降低了 CPU 负载并释放了内存带宽。
- 支持真正的异步传输,实现计算与数据传输并行,提高整体吞吐。
- 最大化利用 PCIe 带宽,传输速率可接近总线理论极限。
Efficient Live Migration of LLM Inference
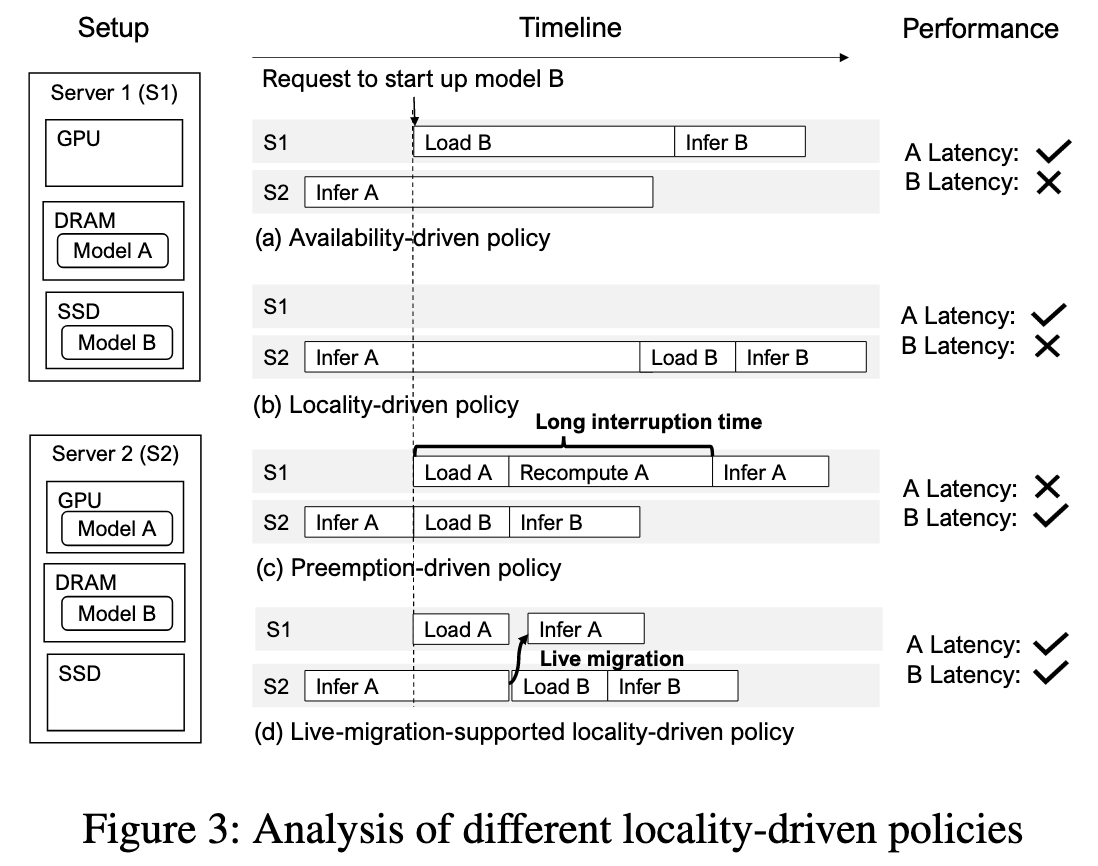
几种不同的迁移策略:
- Availability-driven policy:空闲 GPU 优先
- Locality-driven policy:本地性优先, DRAM > SSD
- Preemption-driven policy: 抢占式
- Live-migration-supported locality-driven policy:先在另一台服务器上进行模型加载,加载完成后再把当前推理的中间结果转移过去
迁移的两个要求:
- the migrated inference state must be minimal to reduce network traffic
- the destination server must quickly synchronize with the source server’s progress to minimize migration times
对于要求 1,论文采用了只迁移 tokens 而不是庞大的 KV Cache;对于要求 2,论文提出了一个 insight:
- 重计算 KV-Cache (Recomputing):当给定一个已知的 token 序列(比如用户输入和已经生成的部分回复)时,一次性地、并行地处理所有这些 token,来计算出它们对应的 KV-Cache。这个过程也被称为“预填充(Prefill)”或“提示处理(Prompt Processing)”。虽然计算量大,但因为可以并行处理,所以速度非常快。
- 生成新 Token (Generating):在已有 KV-Cache 的基础上,逐个预测并生成下一个未知的 token。这是一个自回归(autoregressive)的过程,必须生成完第 N 个 token 才能去生成第 N+1 个,因此是串行的,速度相对慢得多。
论文的核心洞见就是:对于同样数量的 token,操作1(重计算)比操作2(生成)快得多,通常要快一个数量级(即10倍左右) 。
ServerlessLLM “追赶式”多轮迁移利用了“重算 KV-Cache 远快于生成新 token”这一速度差异,通过以下步骤迅速收敛并实现近零中断:
- 首轮迁移:
- 源服务器 A 已生成 N(如1000)个 token,开始迁移时一次性发送给目标服务器 B。
- B 对这 N 个 token 快速重算出完整的 KV-Cache;此期间 A 继续慢速生成新 token。
- 差距缩小:
- 当 B 完成重算时,A 只新增了较少的 token(如100 个),B 仅落后这一小段。
- 多轮迭代:
- A 再将这少量新增 token 送给 B,B 再次重算,同时 A 再生成更少的新 token(如10 个)。
- 每轮同步的 token 数量急剧减少,迁移差距迅速“收敛”。
- 无感切换:
- 最后一轮只需极短暂停,同步最后几枚 token,即可将服务切换到 B 上,达到几乎无感知的实时迁移效果。
在论文 5.3 的描述中,除了首轮迁移,只会有一轮迭代
Startup-Time-Optimized Model Scheduling
This scheduler processes loading tasks from the request router and employs two key components: a model loading time estimator and a model migration time estimator.
这是一个智能的集群调度器,其目标是为新来的模型加载请求选择一个最优的服务器,以最小化模型的启动时间 。
精确的时间估算:调度器内置了成本模型,可以精确估算在不同服务器上从不同存储层级(SSD、DRAM)加载一个模型所需的时间,以及将一个正在运行的任务迁移到另一台服务器所需的时间 。
全局最优决策:当一个新请求到达时,调度器会评估所有可能的方案 。例如,它可以选择一台空闲的服务器 A(需要从 SSD 加载模型),也可以选择一台繁忙的服务器 B(其 GPU 正在运行任务 C,但内存中缓存了所需模型),然后将任务 C 实时迁移到服务器 D,再在服务器 B 上启动新请求。调度器会计算所有方案的总耗时,并选择最快的一个
思考与评论
工程性,系统性很强,有一种在看 Google 早期"三架马车"论文的感觉