回应我在 EdgeMoE 结尾提出的暴论:所有需要离线 Profiling 的工作都应该由 LLM 厂家在训练时实现。
我们不应该问“如何把云端模型塞进本地设备?”,而应该问“如果我们从一开始就为本地设备的限制而设计,一个大语言模型会是什么样子?”。
SmallThinker 模型家族是一个从零开始、原生为本地部署而设计的全新架构。它将本地设备的弱计算能力、有限内存和慢速存储这三大限制,转化为了架构设计的核心原则。
Insights
- Sparsity is all you need
- Predict-and-prefetch is all you need
Model Architecture
Fine-Grained Mixture of Experts
SmallThinker 旨在引入稀疏性来大幅降低计算负载,该架构由四个关键部分组成:
- 基础 MoE 架构:模型采用了 MOE 架构。4B 模型配置了 32 个专家,而 21B 模型则配置了 64 个专家。这种设计可以在保持巨大总参数量(从而保证模型的知识容量)的同时,显著减少单次推理所需的实际计算量
- 基于稀疏 ReGLU 的 FFN: 为了在MoE的结构稀疏性之上实现第二层稀疏,每个专家内部都使用了ReGLU激活函数。ReLU系列的激活函数天然会使许多神经元的输出变为零,从而在专家内部诱导出“神经元级别的稀疏性”。这意味着,即使一个专家被路由激活,其内部仍有大量神经元是不参与计算的。这为后续的计算优化提供了基础,进一步降低了计算和I/O开销
- 预注意力路由:最具创新性的设计之一
- 传统做法:在大多数 MoE 模型中,Router 模块位于 Attention 模块之后
- SmallThinker: 将 Router 放在了 Attention 模块之前
- 允许模型在执行计算密集型的注意力操作的同时,提前预测出接下来需要哪些专家。推理引擎可以利用这个时间窗口,并行地从慢速的SSD中 prefetch 所需专家的参数到内存中。当注意力计算完成时,专家参数也已准备就绪,从而隐藏 I/O 延迟
- DP-Groups 全局负载均衡损失: 解决一个 MoE 训练中的固有矛盾:既要让专家“专业化”,又要避免训练不均衡
- SmallThinker 采用了一种更宽松的、在数据并行的分组(DP-Groups)内进行负载均衡的策略。这允许不同的小组根据自己的数据“培养”出各自的专业化专家,既实现了功能上的专业化,又保持了训练的稳定性,且几乎不增加额外的训练开销
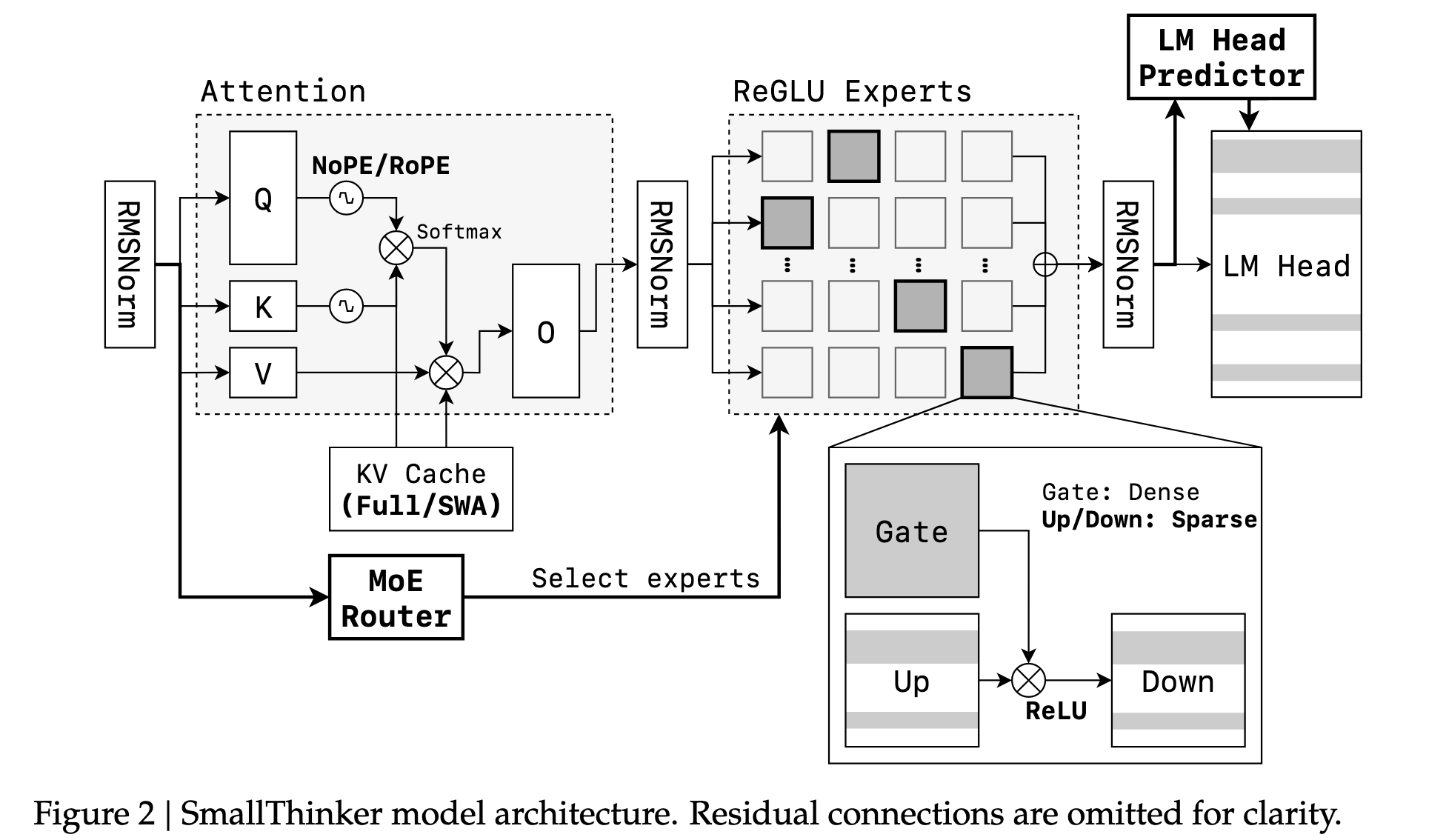
NoPE-RoPE Hybrid Sparse Attention
目标:在模型性能和 KV Cache 效率之间取得最佳平衡。
架构设计:模型采用了“NOPE-ROPE混合稀疏注意力”架构。它在模型的不同层之间以一个1:3的重复模式运行:
- 1 层全局注意力:使用无位置编码(No Positional Embedding, NoPE)的全局注意力,能够捕捉全局上下文信息
- 3 层滑动窗口注意力:紧接着是三层使用旋转位置编码(Rotary Position Embedding, RoPE)的滑动窗口注意力(Sliding Window Attention, SWA),窗口大小为4096。这种注意力只关注一个局部窗口内的信息,计算和内存开销都小得多。
效果:通过战略性地、有节制地使用昂贵的全局注意力,并主要依赖高效的滑动窗口注意力,这种混合设计在很大程度上保留了模型处理长上下文能力的同时,显著降低了 KV Cache 的内存占用。
- 通过两级稀疏结构(MoE 稀疏 + ReGLU 神经元稀疏)解决了计算能力有限的问题
- 通过预注意力路由器和专家专业化解决了 I/O 速度慢的瓶颈
- 通过混合稀疏注意力机制解决了内存容量有限的挑战
Inference Framework for Local Devices
两大主题:
- 内存效率
- 稀疏计算
Memory-Efficient Inference
此部分专注于解决当模型大小超过设备可用内存时,如何克服慢速存储(如SSD)带来的I/O瓶颈问题。
- 专家卸载 (Expert Offloading):框架实现了一个参数卸载机制,允许将一部分不常用的 MoE 专家参数存储在 SSD 上,而只在内存中保留核心部分和常用专家。这是在内存极度受限设备上运行大模型的基础。
- 专家缓存 (Expert Cache):为了减少对慢速 SSD 的访问,框架利用了模型训练时培养出的“专家激活局部性”特性(即特定任务倾向于激活特定的一组专家)。它在所有 MoE 层之间实现了一个共享的专家缓存,并采用 LRU 替换策略,从而将最常被访问的“热”专家保留在高速的 DRAM 内存中,有效降低了 SSD 的访问需求。
- 专家预取流水线 (Expert Prefetching Pipeline):这是解决 I/O 延迟的关键创新。该框架充分利用了模型架构中的“预注意力路由器”。
- 当模型进行计算密集型的 Attention 运算时,预注意力路由器已经提前给出了下一步需要哪些专家的信息。
- 推理框架利用这个时间窗口,并行地启动I/O操作,从SSD中预先读取所需专家的权重。
- 通过将 I/O 操作与计算任务重叠,创建了一个高效的流水线,从而有效地隐藏了 SSD 的访问延迟。结合高命中率的缓存策略,这套机制使得模型在需要从 SSD 加载专家时,其性能表现几乎与完全在内存中运行一样快。
Sparse Inference
此部分专注于利用模型固有的稀疏性,通过跳过不必要的计算来减少 CPU 的运算负载,从而提升推理速度。
ReGLU 稀疏性利用:如前文所述,ReGLU 激活函数会在专家内部产生超过 60% 的神经元级稀疏性。
- 推理框架并非简单地进行无效的乘零运算,而是实现了一种选择性计算策略。它会先计算 gate matrices 的值,然后根据 ReLU 的输出,只计算上行和下行投影矩阵中与之对应的非零神经元。
- 为了将这种理论上的优化转化为实际速度,框架开发了高度优化的融合稀疏 ReGLU FFN kernels,利用 SIMD(单指令,多数据)向量化指令进行高效的并行处理。
LM Head 稀疏性利用:模型的最终输出层(Language Model Head)因其巨大的尺寸(隐藏层维度 × 词汇表大小)而成为一个主要的计算瓶颈。
- 为了缓解这个问题,框架引入了一个专门的、轻量级的预测器模块 (predictor module)。
- 在推理时,该预测器会首先识别出词汇表中最有可能被激活的一小部分词汇(行)。
- 随后,推理系统只计算这些被预测出的行的logits值,而将其余所有行的logits直接置零,从而避免了大量的冗余计算,优化了资源利用。
ReGLU 的稀疏性部分竟然只使用了选择性计算,没有使用 Predict-and-prefetch?
难道说打算在 PowerInfer-3 中再写?或者是说现在的 Prefetch MoE + Selective computation 已经完全够用了?
Inference Performance Evaluation
这一部分通过实验数据验证了上述推理框架的有效性。所有优化都在 PowerInfer 框架内实现。
端到端内存内性能:在内存充足的情况下,得益于对专家级、ReGLU和LM Head三种稀疏性的全面利用,SmallThinker在PC、智能手机和嵌入式设备上均表现出卓越的推理速度,相比 Gemma3n-E4B 等模型提升高达65%。
专家卸载性能(内存受限)
- 在 8GB 内存限制下,SmallThinker-21B-A3B 的吞吐量比 Qwen3-30B-A3B 高出 85 倍,并且其推理速度几乎与完全在内存中运行的 Gemma3n-E4B 持平。
- 论文指出,其他模型在这种情况下会因低效的内存交换和对 SSD 的随机细粒度读取而遭受严重的性能损失。相比之下,SmallThinker 的预取流水线成功地克服了这一瓶颈。
- 在 1GB 内存限制下,4B 模型也展现了类似的巨大性能优势。
通过专家预取流水线和智能缓存机制,成功解决了在内存受限设备上的 I/O 瓶颈;同时,通过对多层次稀疏性的计算优化,显著降低了 CPU 的运算压力。
Thoughts
LLM tailored for NPU 还会远吗?
未来是 LLM/Inference System 适应 NPU,还是 NPU 适应 LLM?