Background
Disaggregated databases typically decouple the system into:
- an execution layer, which requires substantial computational resources
- a storage layer, which necessitates significant storage capacity
Concurrency Control (CC) is a key function module in databases
The resource requirements of CC are neither consistent
- With SQL execution: execution prefers relatively more compute nodes but CC prefers fewer nodes
- With data storage: data storage nodes have substantial storage capacities but limited computing resources
Yet, most existing cloud-native databases simply couple CC either with the execution layer or the storage layer.
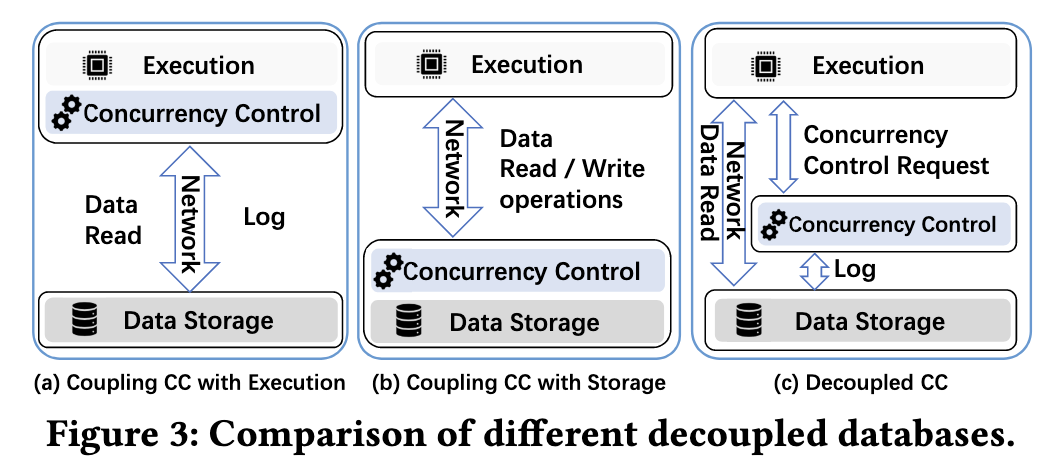
Databases like Aurora and PolarDB couple CC with transaction execution
- raises coordination overhead by involving more nodes in conflict resolution, scaling too much nodes will hurts the system performance
- Incur redevelopment costs for resolving transaction conflicts due to the similarity of CC algorithms
Databases like Solar and TiDB couple CC with data storage
- Coupling CC with storage makes CC hardly elastically scalable.
- Managing CC with limited computation resources provided by storage nodes could hurt performance.
Core Insight
The core of CC is resolving read-write conflicts on data items without caring about data types.
So we can provide a CC layer which receives the read and write sets of transactions and output the transaction result.
System Architecture
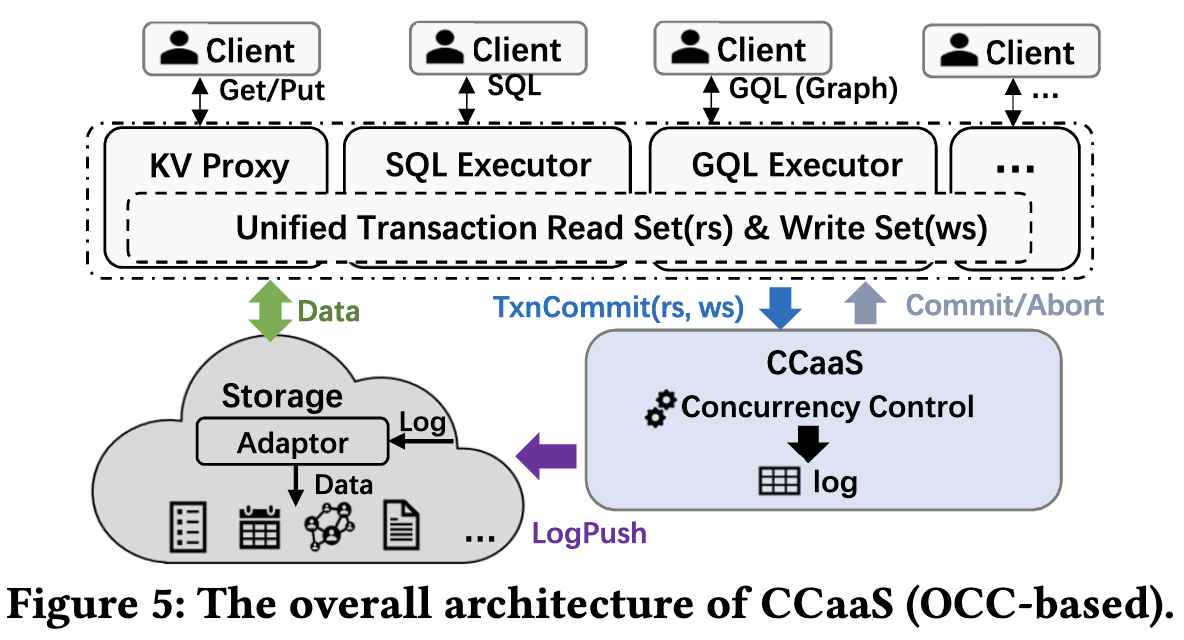
During CC conflict resolution, the readset and writeset are used to detect read-write conflict and write-write conflict.
OCC is an ideal choice for decoupling CC, as it requires only slight modifications to the transaction commit process, which sends the read and write sets of transactions to CCaaS for conflict resolution.
General Process:
- Execution layer read data from storage node
- Execution layer to CCaaS: Transaction info with readset and writeset
- Conflict resolution in CCaaS, then make transaction decisions
- CCaaS send back decisions to the execution layer and push log to the storage node
- Storage node applies logs
Design
CCaaS Overview
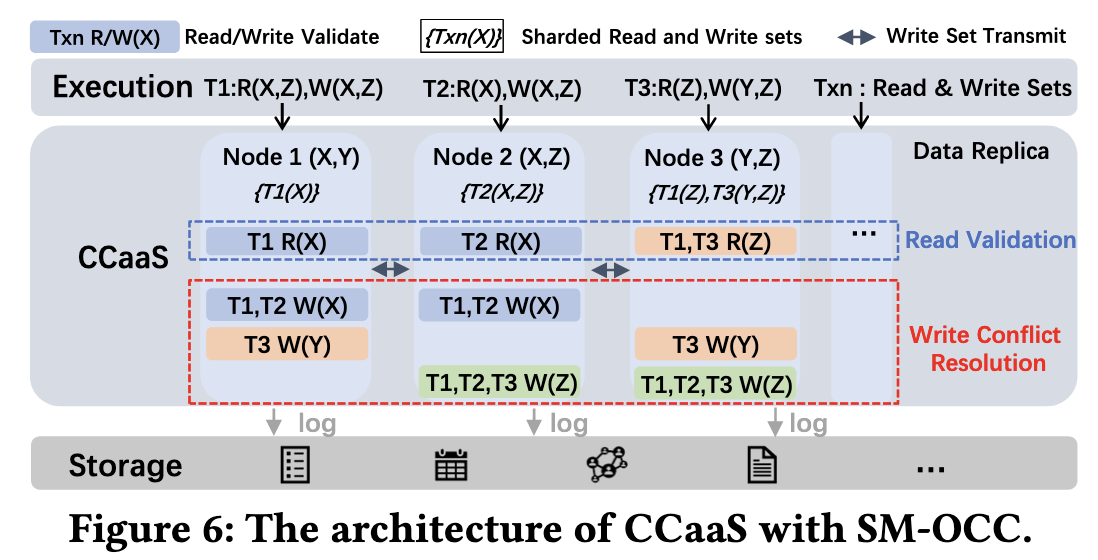
In CCaaS:
- Each node maintains several shards of committed transaction metadata
- Each node acts as a master, allowing nodes to manage transaction conflicts independently
- Nodes receive read and write sets (referred to as transactions) and partition them based on a sharding strategy, routing subtransactions to corresponding nodes for conflict resolution.
Sharded Multi-Write OCC
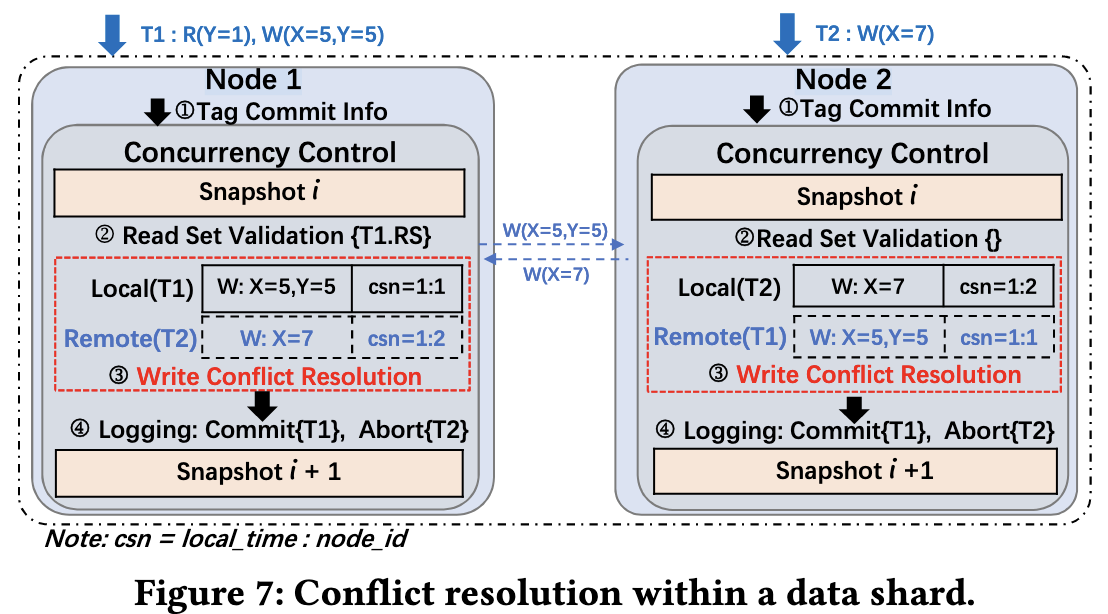
- CCaaS divides physical time into epochs
- Each node collects read and write sets (transactions) and packs them at epoch granularity based on the reception time
- Each transaction is identified by the commit sequence number (CSN)
- The CSN of a transaction is composed of
local time+node id
- The CSN of a transaction is composed of
- Nodes synchronize transactions with each other at epoch granularity, and operate in an epoch manner
SM-OCC’s procedure:
- Read Set Validation
- Write Set Validation
Read Set Validation
Validate the read sets of locally received transactions based on snapshot $i$
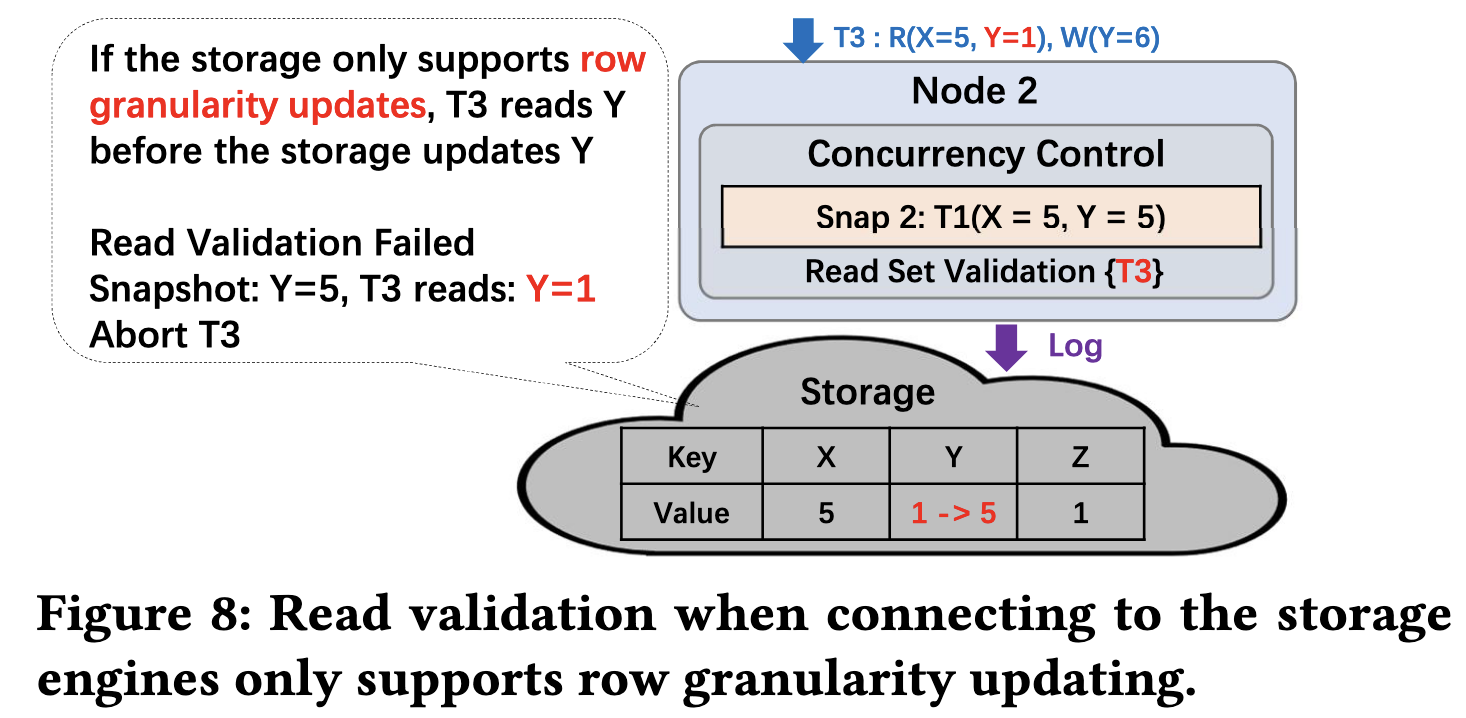
One specific problem:
A transaction (T1) atomically updates two separate items (e.g., X and Y) in the CCaaS layer. CCaaS then sends these two updates to the physical storage layer. Because the storage might apply these updates one by one (X first, then Y), a brief window exists where the physical data is inconsistent (e.g., X is new, but Y is still old). If another transaction (T3) reads from storage during this exact window, it sees a “torn” or “half-done” state that should never logically exist.
Solution: Validation Against the Logical Snapshot
When the second transaction (T3) tries to commit, it presents what it read to the CCaaS layer. The CCaaS layer maintains the correct, logically consistent state of the database in its own snapshot. It compares what T3 read against this correct snapshot, finds a mismatch, and realizes T3 read inconsistent data. To protect data integrity, CCaaS aborts T3.
Why this would happen?
This specific problem is a direct consequence of decoupling the logical commit layer (CCaaS) from the physical storage layer.
In the CCaaS architecture, however, there are two sources of “truth”:
- The logical truth in the CCaaS snapshot (which is always consistent).
- The physical truth in the storage layer (which can be temporarily inconsistent due to update delays).
Write Set Validation
The algorithm’s primary goal is to be deterministic: every node, given the same set of transactions for an epoch, must independently arrive at the exact same commit/abort decisions without needing to communicate with other nodes during the decision process.
The algorithm can be understood in two main stages for each transaction being validated:
- Stage 1: Validation Against the Past (The Global State)
- Stage 2: Validation Against the Present (The Current Epoch)
Validation Against the Past
- For each write operation (e.g.,
Insert,Update,Delete) in a transaction’s write set, it checks theGlobalWriteVersionMap. This map represents the committed state of the database before the current validation epoch began. - Logic:
- Detect trying to
Insertan existing key - Detect trying to
UpdateorDeletea non-existent key
- Detect trying to
Validation Against the Present
- It uses a temporary map called
EpochWriteVersionMapto track which transaction has “claimed” a key in the current epoch. - Logic:
- Record the transaction write set in
EpochWriteVersionMap, the transaction with smaller CSN can claim the key(winner) - Loser will be recorded in
EpochAbortSet - Any transaction not in the
EpochAbortSetis considered committed - The writes from all committed transactions are then used to update the
GlobalWriteVersionMap, establishing the new database state for the next epoch’s validation.
- Record the transaction write set in
Sharded Multi-write OCC
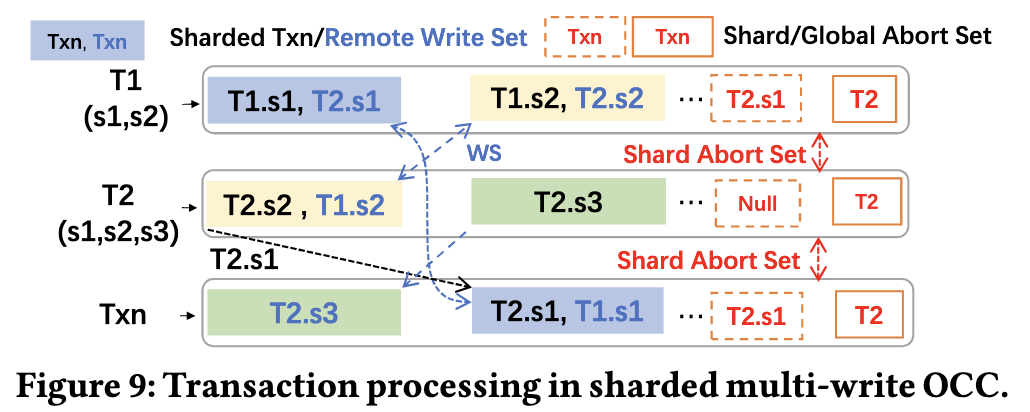
To solve the atomicity problem, the system performs one final synchronization step.
- All nodes broadcast their local
EpochAbortSet (Shard)lists to every other node in the cluster - Each node receives the abort lists from all other nodes. It then constructs a final, globally consistent abort set
- If any sub-transaction of a transaction
Tappears in any of the received lists, then the entire transactionTis marked for abortion.
- If any sub-transaction of a transaction
- Using this global abort set, every node now has the complete picture. It can definitively determine which multi-shard transactions must be aborted.
Fault Recovery
- Failure in the execution layer
- Execution layer is stateless
- Failure in the CCaaS layer
- Two Raft protocols are used:
Txn Raftbacks up transactions, whileShard Raftdetects failed nodes. - If a node fails before exchanging data: The entire epoch is aborted and re-executed to prevent inconsistent decisions.
- A new leader uses the backups to ensure all survivors resolve conflicts with complete information, guaranteeing consistency.
- Two Raft protocols are used:
- Failure in the storage layer
- Solely on the native fault tolerance of its data store systems, without redundancy