Intensive Reading
Author Info
- Zhenliang Xue: From IPADS.
- Yixin Song: First author of PowerInfer.
- Zeyu Mi (糜泽羽): He is an associate professor at School of Software, Shanghai Jiao Tong University (SJTU).
- Haibo Chen [IPADS]: Director of Institute of Parallel and Distributed Systems.
Background
Sparsity
FFN 的参数占比大,稀疏化特征也明显(特别是在使用 ReLU 时),所以可以在执行计算前利用一个 predictor 来预测哪些神经元会被激活,从而降低计算和 I/O 开销。
PowerInfer2 还探索了 LLM 推理过程中的动态稀疏性:
- 当批次很大时,对于任何一个神经元,只要它被输入中的至少一个激活,它在这一步的计算中就不是稀疏的。由于不同输入会激活不同神经元,其聚合效应导致大量神经元被激活,形成稳定、密集的“热点”,整体稀疏度显著降低。
- 由于某些序列会更早终止,所以有效批次的大小也会动态波动。这个实时变化导致了模型的计算模式在一个任务的生命周期内,会从一个接近稠密的模式平滑地过渡到一个高度稀疏的模式。
Mobile Hardware Characteristics
与 PC 相比,手机的硬件有两个特点:
- Heterogeneous computing capabilities with distinct sparse computation characteristics.
- CPU 更擅长稀疏计算
- NPU 更擅长稠密计算
- GPU 比 CPU 和 NPU 都更慢,而且在推理中使用 GPU 会影响设备的渲染帧率
- 移动 LLM 推理框架应同时利用异构处理器,以最大限度地利用共享内存带宽
- Distinct storage architecture with unique I/O characteristics.
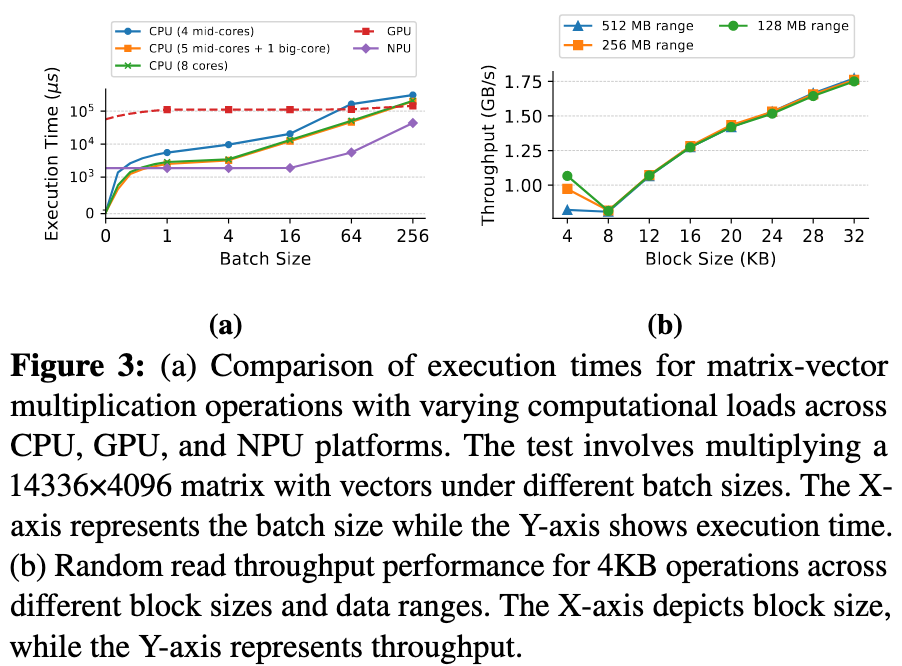
- 读的块大小越大,吞吐量越高
- 数据范围越小,吞吐量越高
- 频率越高的 CPU core 读取时吞吐量越高
- UFS 并发能力有限
Challenges
Due to smartphones’ limited computing and memory resources, only small language models (SLMs) can be deployed, significantly compromising model quality and capabilities.
PC-centric solutions suffer from severe execution speed degradation on smartphones due to two key hardware gaps between smartphones and high-end PCs:
- The Sparse Computing Gap: Smartphones’ mobile NPUs, while offering superior performance for dense computations compared to mobile CPUs, lack dedicated hardware support for sparse operations and struggle with unstructured sparse computations.
- The Storage Performance Gap: The Universal Flash Storage (UFS) in smartphones faces severe performance limitations compared to PC’s NVMe SSDs.
UFS 追求低功耗和高能效。
Insights
Fine-grained neuron cluster abstraction for mobile LLM inference:
- Decomposing matrix operations into neuron clusters as the basic processing unit, which enables flexible scheduling and efficient I/O-computation pipelining.
- For computation: neuron clusters with dense activations are processed on NPU, while sparse clusters use CPU
- For storage: a fine-grained pipeline mechanism that coordinates cluster-level computation and I/O operations
Two principles for redesigning LLM inference to address smartphone-specific hardware constrains:
- It is crucial to maximize performance by intelligently distributing tasks between NPU and CPU based on their respective computational strengths.
- Dense activations are processed on NPU, while sparse clusters use CPU.
- I/O-Aware Orchestration to address the mismatch between traditional matrix-based computation granularity and mobile storage performance.
- Enable efficient overlap between computation and I/O, effectively hiding storage access latency.
- Allow the system to choose specialized I/O access patterns for different neuron clusters, improving storage bandwidth utilization during inference.
Approaches
PowerInfer-2 利用了神经元簇的抽象,并基于两个原则进行构建:
- Sparsity-Aware Adaption: Prefill phase 使用 NPU 计算,在 Decoding phase 使用 CPU 和 NPU 的混合计算方式并动态调整。
- I/O-Aware Orchestration: 通过细粒度流水线和针对不同类型LLM权重的差异化I/O策略优化UFS存储访问。
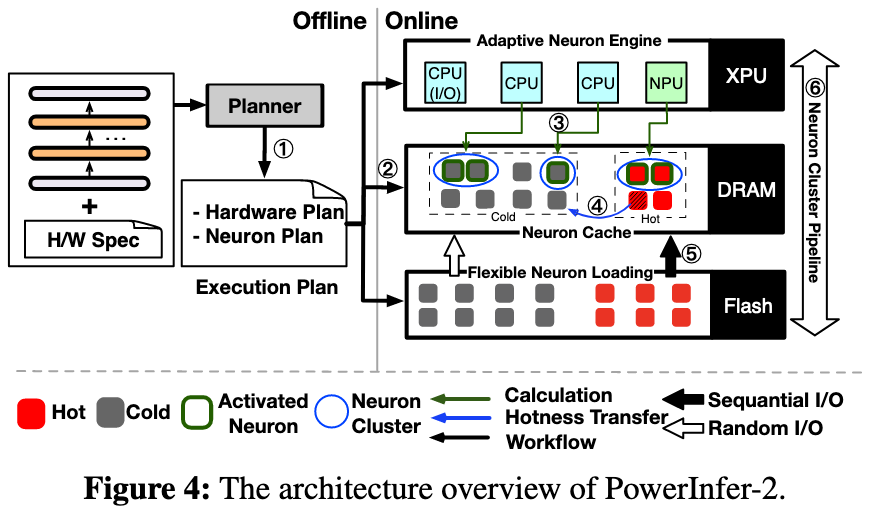
整体流程和 PowerInfer 类似,分类两个大阶段:
- Offline Profiling and Planning: 区分出冷热神经元簇, 并生成对应的执行计划,包括如何划分神经元簇和如何配置对应的硬件资源
- Online Inference:
- Prefill phase: 使用 NPU 进行计算,单独用一个 CPU core 执行并行权重加载
- Decoding phase: 使用 CPU-NPU 混合策略,核心思想就是把热神经元簇分配到 NPU 上,把冷神经元簇分配到 CPU 上
- 对于热神经元簇,直接使用 NPU 进行稠密计算
- 对于冷神经元簇,采用一个 online predictor 来降低计算开销(和 PowerInfer 以及 LLM-Flash 类似)
在加载权重时,采用了神经元簇级流水线,让慢速的 I/O 操作被“隐藏”在了 CPU 的计算周期之下,实现了计算和 I/O 操作的最大化并行。
Adaptive Neuron Engine
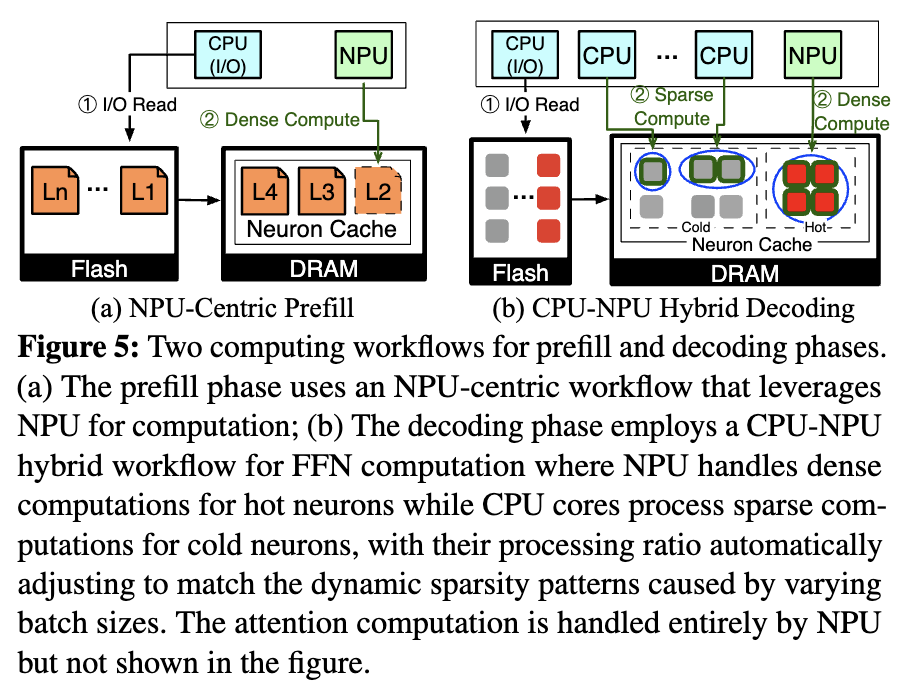
在 Prefill 阶段,虽然单个 token 表现出高稀疏性,但是整个序列在计算时稀疏性会很低,所以直接采用 NPU 进行稠密计算 (Figure 5a)。
在 Decoding 阶段,采用了 CPU-NPU 混合的策略:NPU 对其热神经元簇执行密集矩阵乘法,而 CPU 内核则使用基于 Predictor 的方法处理冷神经元簇 (Figure 5b)。
在动态进行 CPU-NPU 调整时,考虑到 NPU的静态图执行模型,调整其计算负载需要加载新的计算图。所以在离线阶段,PowerInfer-2 会准备多个 NPU 计算图,每个计算图都针对特定的批处理大小和相应的热神经元比例进行了优化。
In-Memory Neuron Cache
这部分好像对 LLM-Flash 的内容有误解,LLM-Flash 中说明捆绑共同激活的神经元会带来负面效果,实际并没有这么做。
而且个人感觉捆绑共同激活的神经元带来的热神经元被反复,冗余地加载带来这一现象很好解决,加个缓存就行了?
PowerInfer-2 提出了一个多区域缓存:
- Fixed Region
- 缓存 Attention weights 和 KV Cache
- 这部分数据在整个推理过程中是持续、密集使用的。因此,该区域的权重在启动时被一次性加载,并常驻内存,从不被换出。
- Hot Region
- 为 NPU 执行的稠密计算服务
- 组织粒度:簇级别。进入这个区域的神经元不是单个的,而是被组织成一个大的、统一的“热神经元簇”。这个簇是一个密集的矩阵块,内部已经整合了 FFN 的 Gate、Up 和 Down 三个子矩阵的相应部分。
- 采用簇级的LRU(Least Recently Used)算法
- Cold Region
- 为CPU执行的稀疏计算服务
- 组织粒度:神经元级别
- 采用神经元级的LRU算法
Neuron-Cluster-Level Pipeline
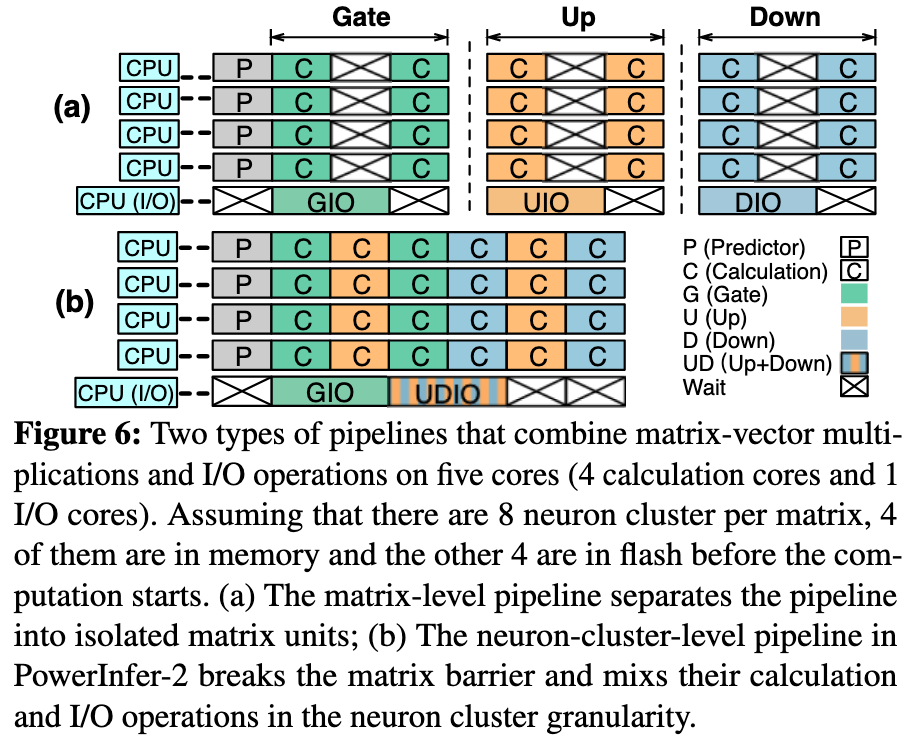
虽然使用了 cache, 但免不了对 cold neuron 的加载,传统的 matrix-level pipeline 粒度太粗了,系统必须等待矩阵中的所有神经元都可用后才能计算下一个矩阵 (Figure 6-a)。
PowerInfer-2 采用了更细粒度的 neuron-cluster-level pipeline 来解决这个问题。
一开始看的时候我还不理解,Gate -> Up -> Down 之间不是有数据依赖关系吗,怎么实现乱序执行的
- 对于单个神经元或者神经元簇来说,其计算必须严格遵循数据依赖关系
- 关键在于:并行和交错(interleaving)不是发生在同一个神经元簇的依赖阶段之间,而是发生在不同、独立的神经元簇之间
Flexible Neuron Loading
PowerInfer-2 针对不同类型的模型权重,采用不同的I/O策略。例如,对热神经元和注意力权重使用高效的顺序读取,对冷神经元使用随机读取。
对于 FFN 层,Gate, Up, Down 矩阵中位置对应的神经元共激活概率高达80%,所以将这些神经元捆绑存储和加载,提高 I/O 效率。
还会根据模型是否被量化以及UFS闪存的特性,智能地选择最优的读取块大小(例如,对于4-bit量化模型,将一个8KB的读取任务拆分为两个4KB的操作会更快)。
Execution Plan Generation
The planner’s primary task is to analyze and classify neurons based on their activation patterns across different batch sizes and hardware I/O characteristics.
This classification process involves:
- Running the model on a diverse dataset (10M+ tokens from Wikipedia and RefinedWeb).
- Tracking activation frequencies for each neuron under various batch sizes.
- Analyzing hardware-specific I/O patterns and computation speeds.
- Categorizing neurons into hot clusters and cold clusters.
Evaluation
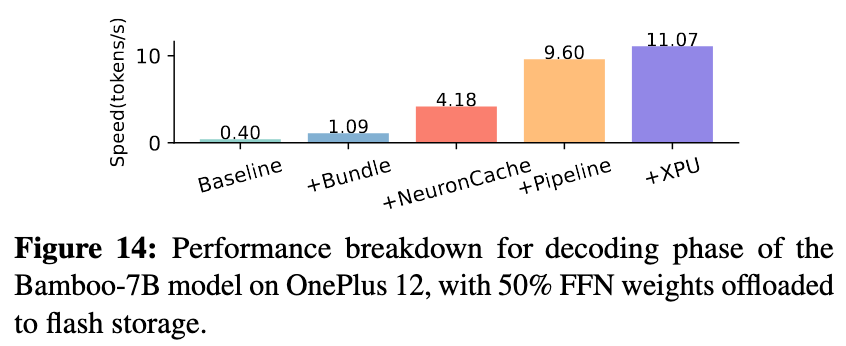
- Baseline (0.4 tok/s):最原始的实现,性能极低。
- + Bundle (1.1 tok/s):通过将FFN中Gate/Up/Down三个矩阵的对应神经元权重捆绑加载,初步优化了I/O效率,带来了2.75倍的提升。验证了论文对跨矩阵神经元激活相关性洞察的正确性 。
- + Neuron Cache (4.18 tok/s):在加入基于温度的多区域、多粒度缓存后,性能飞跃了3.8倍。实验表明缓存命中率高达95%,这证明了其设计的有效性,极大地减少了对慢速闪存的访问,是解决I/O瓶颈最有力的一环。
- + Pipeline (9.60 tok/s):即使有高效缓存,缓存未命中依然存在。在加入神经元簇级流水线后,性能再次提升了2.29倍。这强有力地证明了其计算与I/O并行、隐藏I/O延迟策略的巨大成功。它榨干了硬件的每一分潜力,让CPU在等待I/O时也能处理其他任务 。
- + XPU (11.07 tok/s):最后,启用CPU和NPU的异构协同计算,带来了额外的 15% 性能增益。
所以异构协同计算带来的性能增益没有想象中的高,如何解决 I/O 瓶颈才是最重要的。
Thoughts
When Reading
LLM 在激活参数上的边际效应特别明显,像 PowerInfer 那样,只计算部分神经元,极大降低了计算量和带宽限制,模型的质量却几乎不会退化。
需要对 llama.cpp 代码本身有了解,方便自己做一些 profiling 和 demo.
这部分做实验的话,买手机一定要能 root 的。
Related Works
- PowerInfer Fast Large Language Model Serving with a Consumer-grade GPU
- LLM in a flash Efficient Large Language Model Inference with Limited Memory
- Deja Vu Contextual Sparsity for Efficient LLMs at Inference Time
- A survey of resource-efficient LLM and multimodal foundation models
- STI: Turbocharge NLP Inference at the Edge via Elastic Pipelining