Intensive Reading
Author Info
- Yixin Song - Google Scholar
- Zeyu Mi (糜泽羽): He is an associate professor at School of Software, Shanghai Jiao Tong University (SJTU).
- Haotong Xie (谢昊彤)
- Haibo Chen [IPADS]: Director of Institute of Parallel and Distributed Systems.
Background
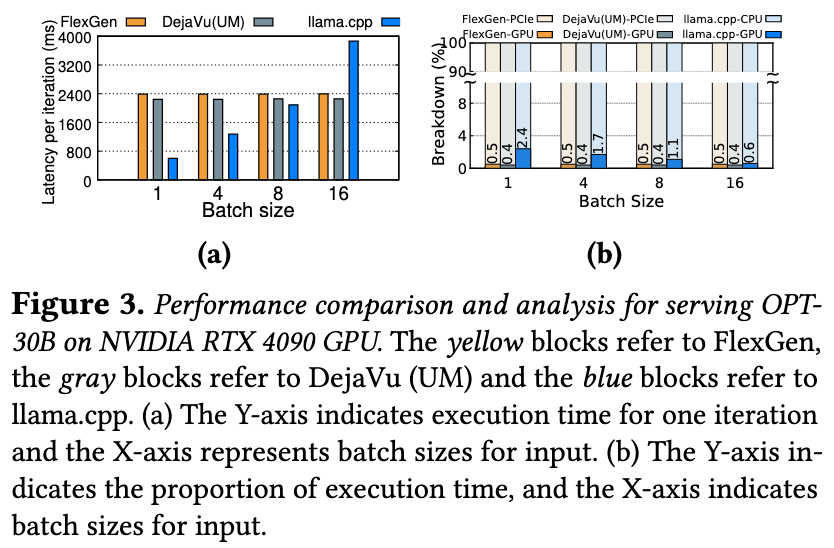
Local deployments focus on low latency in processing small batches.
LLM inference exhibits notable sparsity in neuron activation, a phenomenon observed in both self-attention and MLP blocks.

- The offloading technique leverages the CPU’s additional computational and memory resources.
- GPU-centric offloading utilizes CPU memory to store portions of the model parameters that exceed the GPU’s capacity.
- Lead to substantial per-token latency mainly due to frequent data transfers between GPU and CPU. Over 99.5% of processing time is consumed by transferring LLM weights from CPU to GPU.
- Hybrid offloading distributes model parameters between GPU and CPU, splitting them at the Transformer layer level.
- The CPU processes its layers first, then sends intermediate results to the GPU for token generation.
- The CPU, with higher memory but lower computational power, ends up handling 98% of the total computational time.
- GPU-centric offloading utilizes CPU memory to store portions of the model parameters that exceed the GPU’s capacity.
Challenges
- Deploying LLMs on consumer-grade GPUs presents significant challenges due to their substantial memory requirements.
- The inference process is fundamentally constrained by the GPU’s memory capacity.
Insights
Power-law Activation
- Exploiting the high locality inherent in LLM inference, characterized by a power-law distribution in neuron activation.
- A small subset of neurons, termed hot neurons, are consistently activated across inputs, while the majority, cold neurons, vary based on specific inputs.
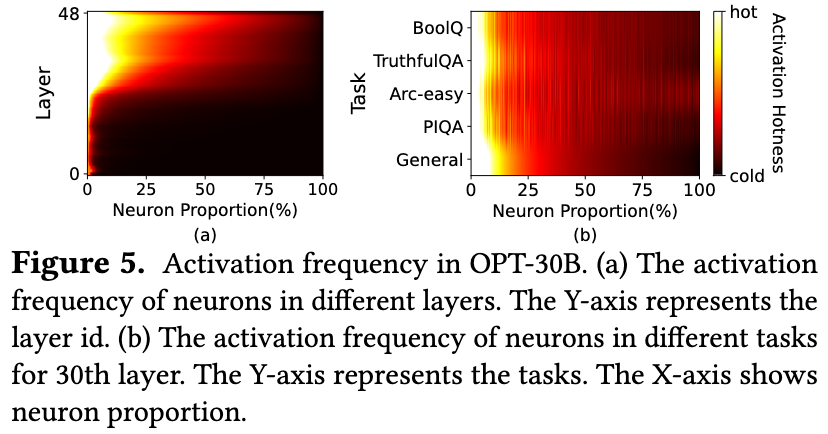
- Hot-activated neurons are preloaded onto the GPU for fast access, while cold-activated neurons are computed on the CPU, thus significantly reducing GPU memory demands and CPU-GPU data transfers.
Fast In-CPU Computation

If activated neurons reside in CPU memory, computing them on the CPU is faster than transferring them to the GPU, especially with the small number of activated neurons and the small batch sizes typical in local deployments.
Approaches
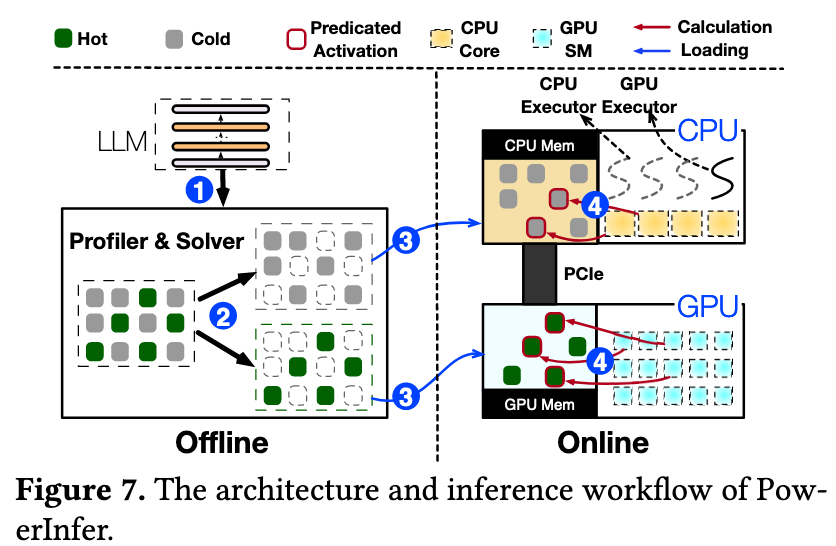
PowerInfer proposes a neuron-aware offloading strategy and an inference engine by fully leveraging the high locality insights.
针对于冷热神经元的洞察,PowerInfer 将频繁激活的神经元的权重预加载到 GPU 中,而不太活跃的神经元的权重则保留在 CPU 上。
为了进一步降低推理延迟,推理引擎利用一个在线的预测器做预测,只计算那些预测会被激活的神经元。
针对于 CPU 计算速度的洞察,PowerInfer 让 GPU 对热神经元计算,让 CPU 对冷神经元计算,降低了权重传输到 GPU 的开销。
论文中也提到,PowerInfer 的性能与模型的稀疏度直接相关。
一个简单的流程就是:
- 对于一个 LLM,先离线跑一个数据集做 Profiling,收集每个神经元的激活频率数据。
- 根据分析器收集到的数据,将神经元划分为“热”和“冷”两类。然后将神经元的最佳放置问题建模为一个整数线性规划问题。
- 根据离线阶段生成的策略,预先加载到 CPU 和 GPU 内存上。
- 对于每个输入,predictor 预测会被激活的神经元,跳过对未激活的神经元的计算。
- CPU 和 GPU 分别计算自己的结果,然后 CPU 将计算结果传输给 GPU 做最后的整合。
- 冷热神经元
- 基于它在处理大量不同输入时被激活的统计频率(由 Profiler 离线区分)
- 热神经元:无论输入什么内容,都经常被激活的一小部分神经元
- 冷神经元:很少被激活,且其激活行为高度依赖于特定输入的大多数神经元
- 激活/未激活神经元
- 一个神经元在某个特定时刻的实时状态(由 Predictor 在线预测)
- 激活神经元:对于当前正在处理的这个输入token,其计算结果经过激活函数(如ReLU)后不为零的神经元 。它将对下一层的计算产生影响
- 未激活神经元:对于当前输入token,其计算结果为零或负数,经过激活函数后输出为零的神经元 。它在本次计算中被“跳过”,不产生任何影响
“冷/热”的分类和“激活/未激活”的状态是两个正交的维度。
- 热神经元的特点是数量少,但访问频率极高,将这个小而关键的热点数据集预先加载到 GPU 中,可以最大化地利用 GPU 强大的计算能力来处理绝大部分的计算任务。
- 冷神经元虽然不常被激活,但它们的数量极其庞大,占据了模型参数的绝大部分
- 这导致只能放在 CPU 内存中
- 如果仅仅是把冷神经元“存放”在 CPU 内存,而在需要时再把它们的权重传输到 GPU 上计算,那么每次激活都会涉及通过缓慢的 PCIe 总线进行数据传输。这种临时传输的延迟非常高,会严重拖慢整个推理过程。
- PowerInfer 的第二个关键 insight: 对于那些偶尔被激活的少数冷神经元,将其权重从 CPU 传到 GPU 再计算,其总耗时反而比直接在现代 CPU 上计算要慢。
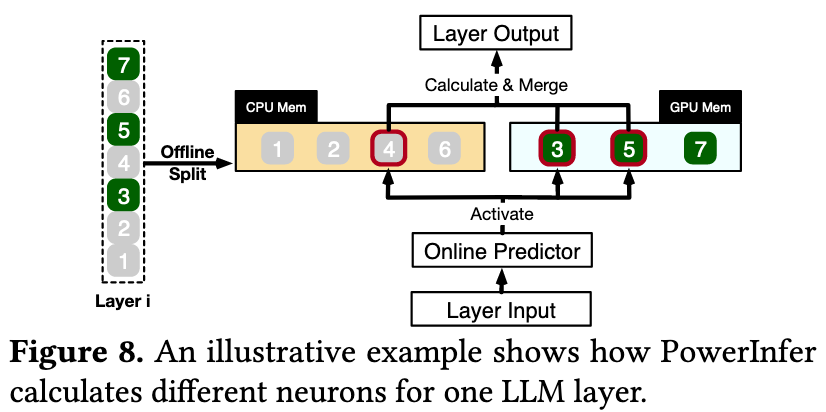
Figure 8 这个例子就展示了 online predictor 预测 4,3,5 号神经元会被激活的情况。
对于每一层,PowerInfer 都训练了 non-fixed-size predictor 来做预测。
Predictor 的大小与模型本身的稀疏度和内部偏度有关,这部分凭直觉也很好理解:如果模型本身就很稀疏,加上可能会激活的神经元都比较聚集,那么 predictor 预测起来就越轻松,参数量也会更小。
在推理开始前,PowerInfer会构建一个计算有向无环图(DAG),图中的每个节点都代表一个LLM推理算子 。这个图被存储在CPU内存的一个全局队列中:
- 在推理过程中,由操作系统创建的两种执行器(pthreads)来管理CPU和GPU上的计算。
- 这些执行器从全局队列中取出算子,检查其依赖关系是否满足,然后将其分配给合适的处理单元执行。
PowerInfer 设计了专门的稀疏计算算子,这些算子直接操作被预测为激活的单个神经元(即矩阵中的行/列向量,避免了传统稀疏计算库中格式转换带来的开销,并能高效地跳过对非激活神经元的无效计算。
Evaluation
可以关注一下消融实验和专项研究部分:
- 消融实验通过逐步添加 PowerInfer 的组件来验证各部分贡献 。
- 仅加入预测器和稀疏算子("+PO"),性能提升约1.87x-3.32x。
- 再加入混合推理引擎("+Engine"),性能提升至2.60x-7.80x。
- 最后集成优化的放置策略("+Policy",即完整的PowerInfer),性能提升达到 3.62x-11.69x。这证明了其基于ILP的神经元放置策略在平衡计算负载和通信开销方面的有效性。
- 神经元感知算子性能:
- 在 CPU 上,PowerInfer 的算子在稀疏度低于 10% 时就已优于稠密计算,而传统稀疏算子(PyTorch sparse)在稀疏度超过 87% 时才能体现优势。
- 在GPU上,其性能与专为 GPU 设计的顶尖稀疏库 PIT 相当,但其优势在于统一的 CPU-GPU 框架,支持混合执行。
- 预测器开销: 在线预测器的执行时间平均只占总推理时间的不到 10%。这得益于其自适应的设计,使得预测器参数量仅占整个 LLM 参数的约 7%。
Thoughts
When Reading
许多 MLSys 工作都遵循 observation-insight-method 范式。
Insight-2 的数据指导性很强 - 当我们在讨论大模型在 CPU 和 GPU 上的执行速度差异时 (小批次),计算能力本身不是瓶颈,数据 I/O 的时间占了很大一部分,权重数据通过 PCIe 总线传输到 GPU 所需的时间,超过了 GPU 本身能节约的计算时间。
无论是这篇文章中提到的 neuron-aware 还是 AWQ 中的 activation-aware,这都说明 MLSys 的研究与 ML 本身结合越来越紧密,不再是简单地将 System 领域的 cache, batch, pipeline, parallelism 等概念直接移植到 ML 中就可以了,要求研究者在 ML 领域也要有极其扎实的功底。
从写作风格上来说,core insights 和 core idea 必须反复在文章不同位置中强调,值得学习。
Predictors 需要额外的训练。
这种通过 Predictors 来预测会被激活的神经元,和 MoE 架构有点类似,但两者稀疏性的来源不同:
- PowerInfer Predictor: 稀疏性来源于模型内生的、自然涌现的激活稀疏性。特别是在使用ReLU等激活函数时,大量神经元的计算结果为负而被置零,导致它们天然处于非激活状态。PowerInfer 通过离线分析发现这一规律,并用在线预测器来动态捕捉它。
- MoE Architecture: 稀疏性是结构性的、被明确设计出来的。MoE 模型由多个“专家网络”(通常是独立的MLP模块)和一个“门控网络”组成。对于每个输入,路由器会决定只激活其中一个或少数几个专家网络进行计算,而其他专家则保持“沉默”。
提出一个问题:两者相加能不能到达 1+1 > 2 的效果呢?